What is a lookup transformation? : Lookup is a transformation a mechanism within Informatica which serves the purpose of referencing data. The source of data, which is stored and referred, could be a database or a flat file. Lookup transformation is built upon this underlying source data. Basically it receives input, matches them against columns, and returns the value through Return Port/Lookup port. Uptill Informatica 8.1 lookup transformation was only passive transformation i.e. it used to return only one row on receiving input. But from 9.1 onwards it could be configured to act active or passive either.
Why it is required? : It actually serves the purpose of referring. So you could have some key values of which you want to find out associated values which are lying in database/flat file. Lookup comes to rescue.
What will happen if I use it? : Once you have lookup transformation, you can now pass those key columns to seek desired information. For example if I pass OrderID I want to know the CustomerID who ordered it. It looks similar to a function call or a seek operation. Well indeed it is that much only. What gets complicated is when you add up other spices to share your lookups, when to build it, persistency etc.
What gets created when I use lookup? : Normally it is going to create a cache file if you have enabled the option of creating lookup cache. Cache file is collection of data which is built by querying source and storing the data in a directory on your hard drive. Any expression requiring search on the source table or file can use this cache file (via lookup). Cache files are always ordered set of data. Along with cache we also have an index file. We will get to it later and explore in more detail each of the term.
However, if you have not selected the option of using Cache then lookup is done by connecting to source directly. Note that lookup on relational tables can be comprehended without using a cache but a flat file lookup has to be cached.
Caches – What are these? How they help? : I would say that cache is very loosely used term in Informatica. Traditionally cache is a mechanism to temporarily store data in a file away from source; so that a network roundtrip to source can be avoided and the locally kept file having data can be used. However in Informatica Cache files built by lookup are collection of not just data but index also. Recall as I said above Cache file is ordered set of data. Ordering happens on key columns which identify a record uniquely. So suppose if I built a lookup on Orders tables, out of data returned by this query Select OrderID, CustomerID from Orders and I seek customerID on the basis of orderID then orderID is the key column and data in cache file will be arranged by OrderID. A separate index file will also be built simultaneously to facilitate search in the data cache file. By default Informatica always indexes on the key column, unless otherwise, you overwrite the SQL query and personally flavor up your ORDER BY clause.
You use cache you gain : How? Well if you do not use cache, then each data queried via lookup is actually seeked from source directly. In case of relational table, connection is established and a query is issued against database to get the associated value of the key columns. Seems messy? Well ofcourse it is. So to avoid such situation we use lookup which have caching enabled.
Sharing up the Lookup : If it seems that the information in lookup can be used by other target load flow also, you can very well share it. By default, when you add a lookup transformation, Informatica Designer enables cache, and the cache it creates is, Static. Another type of cache is Dynamic Cache which actually is yet another cache file but with an added feasibility of having data updated or inserted in the cache. We will discuss more abut dynamic cache in detail, later.
Sharing at mapping level and Sharing at session level : If you want to share the cache file within different load orders in a single mapping, you simply have to enable caching and that’s it. However if you want to enable sharing across mappings then set the cache to be persistent and give a prefix name to cache. Prefix and persistency ensures that the already exiting cache file should not be rebuilt if other mappings are also using it.
Different types of lookups and their (better halves) cache
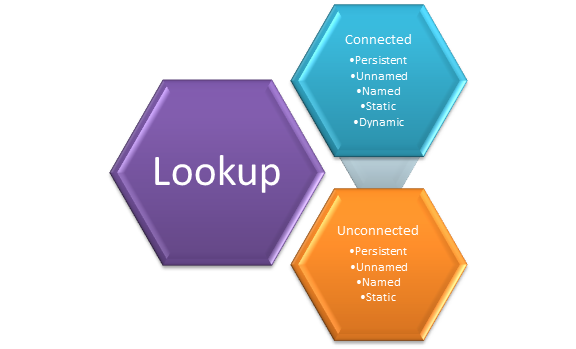
- Types of lookups : There are majorly two types of lookups, Connected and Unconnected. Rest all are cache settings which add more flavor. These are summarized below and we will go through each of them one by one.
- Connected lookup : This type of lookup transformation is a part of pipeline and receives input from upstream transformation. It outputs the port checked as lookup and connected to downstream transformation. (Remember when I say upstream it means given a transformation in focus, the information flow from the preceding transformation, and downstream means information flow from this transformation, to next transformation….mmm may lookup dumb to explain here, but frankly I kept floating in these streams struggling to understand what they mean actually 🙂 ).
- Unconnected lookup : Here we have lookup that is part of mapping however is not a part of any pipeline flow. This lookup acts similar to function call. It is indeed called using notation :LKP.<Lookup name> from any transformation. Rest is same that you pass the key column value to seek the desired value. Note that Unconnected lookup can return only and only one value (port).
- Different Caches : Informatica supports updatable caches and static caches. These are explained below :
- Dynamic Cache : Informatica supports cache which are intelligent, in the sense that if a certain lookup value is not present then it will be inserted in the cache, so that next time when you do a lookup, the value is returned from cache. This type of cache which can be updated is known as dynamic cache. Infact in dynamic cache you can not even insert but also update the values. Suppose based on key columns (columns on which lookup condition is defined) a certain value is fetched from lookup cache. However that value is different from the value entering into lookup, then the cache will be updated to have new values. Updateable lookup is setup by configuring following properties:
- By “associating” the lookup port with incoming port value.
- By unchecking the “ignore in comparison” property for the abovementioned ports.
- By checking the “ignore in comparison” property for the others columns (mostly key columns).
- Static Cache : These are on contrary to Dynamic counterparts, fixed or stagnant collection of values. They are the most simplest form of cache. These are built upon data queried from source; and their data file and index file is non updatable. If the value fetched from lookup is not existing, then NULL is returned else whatever value is present in the Cache, that is returned.
- Dynamic Cache : Informatica supports cache which are intelligent, in the sense that if a certain lookup value is not present then it will be inserted in the cache, so that next time when you do a lookup, the value is returned from cache. This type of cache which can be updated is known as dynamic cache. Infact in dynamic cache you can not even insert but also update the values. Suppose based on key columns (columns on which lookup condition is defined) a certain value is fetched from lookup cache. However that value is different from the value entering into lookup, then the cache will be updated to have new values. Updateable lookup is setup by configuring following properties:
- Persistence / Sharing : Cache can remain alive after the mapping which created it finishes execution, if you set the Lookup cache persistence property. Coming to sharing the cache; well that get’s a bit tricky. It can be shared between different TLO (Target Load Order) within the mapping or even between different mappings/sessions. However sharing cache can be done only if there is no change in the lookup columns and key columns. This is a thumb-rule. Next, if you want to share the cache across session / mapping then it ought to have a name. This name can be set against Cache File Name Prefix setting in lookup transformation. However if lookup is not persistence as soon as session finishes execution, cache file is deleted.
To summarize, given above situations we land up with following lookup and cache settings:-
- Named / Unnamed Cache – Effects scope of Sharing the Cache file across sessions.
- Persistent / Non Persistent Cache – Effects whether lookup cache file can stay alive after session finishes.
- Static / Dynamic Cache – Effects whether you built cache file once or is it updatable.
- Connected / Unconnected lookups – Effects whether lookup returns more than one port or not.
Collectively you can have the following settings:-
- Connected lookup with Static, Persistent, Named/Unnamed Cache
- Connected lookup with Static, Non-Persistent, Unnamed Cache
- Connected lookup with Dynamic, Persistent, Named/Unnamed Cache
- Connected lookup with Dynamic, Non-Persistent, Unnamed Cache
- Unconnected lookup with Static, Persistent, Named/Unnamed Cache
- Unconnected lookup with Static, Non-Persistent, Unnamed Cache
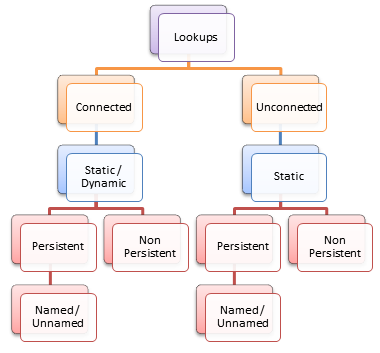
And you cannot have the following:-
- Unconnected lookup with Dynamic Cache (named persistent or whatever):-
As far as sharing of cache goes, you can have following:-
- Static Unnamed with Static Unnamed :- Shared within mapping by default
- Static Named with Static Named :- Shared within mapping and across mappings
- Dynamic with Dynamic Named :- Shared within mapping and across mappings
- Dynamic with Static Named :- Shared within mapping and across mappings
And you can not have the following:-
- Dynamic with Static Unnamed
- Dynamic with Dynamic Unnamed.
One last thing – Two same dynamic lookups in a Target Load Order cannot exist, because cache building is continued process until the entire target has been loaded. Put it simply, until your Target Load Order has finished execution, subsequent dynamic cache usage might differ it from the previous cache values!
(So this seeds up the next part of how lookup is actually created. I will create it shortly…hopeful about it 🙂 )